As a Jira administrator, you’ve probably come across the term LexoRank in Jira. The Jira system settings in both Cloud and Server features a page called LexoRank management and as a Jira Server administrator, you’ve most likely seen it scroll by in the Jira logs. But what is LexoRank? How does it work and why do you need to manage it? That’s what we will explain in this blog.
But first, let’s take a little detour into what ranking is and why it is important.
Rank vs priority?
Ranking is the practice of ordering issues on your backlog, in your sprint or on your board. You may think, that’s what we use priority for. But rank and priority, though related, are different. So, why should you use ranking to order issues instead of priority?
Simply said, priority is about business value and ranking is about how to work. You can’t just fill the next sprint with all the highest priority issues; the size, cost, complexity, risk, dependencies and even availability of resources are also important factors to consider for what should and can be completed in the next sprint.
Also, the priority is often decided based on the relative importance for issues that are related to each other and not for all issues on the backlog. This is also an important reason to choose rank over priority.
Now let’s talk about Jira’s ranking system, LexoRank.
Decomposing the term
Before going into details, let’s first decompose the term LexoRank. It consists of two parts; Lexo and Rank.
- Lexo refers to the word lexicographical, which is basically a fancy way of saying alphabetical ordering.
- Rank refers to the position of Jira issues on a board’s backlog, on a kanban board itself or in the active sprint on a scrum board.
So LexoRank is actually the ordering of issues according to their alphabetical (actually alphanumerical) rank. But how does that work in practice?
Assigning a rank
Each issue that gets created is assigned a rank. A rank is an alphanumeric value that is added to the Rank field of each issue. As soon as you change the order of an issue in the backlog, the value of the Rank field is updated so that it’s alphanumerical order is greater than the issue above it, but lower than the issue below it.
The rank value is absolute and thus unique within the whole Jira instance. The initial rank value a new issue gets is close to but always higher than the rank of other issues in the same context (i.e., a project).
For Advanced Roadmaps (formerly Portfolio) users, this is also the reason why the ranking doesn’t display properly until you start dragging issues within Advanced Roadmaps. The ranking context changes from an individual project context to that of the “Advanced Roadmap”-plan once the rank in Advanced Roadmaps has been changed. Do note that the updated ranks are not applied in Jira until you commit the plan’s changes.
Example
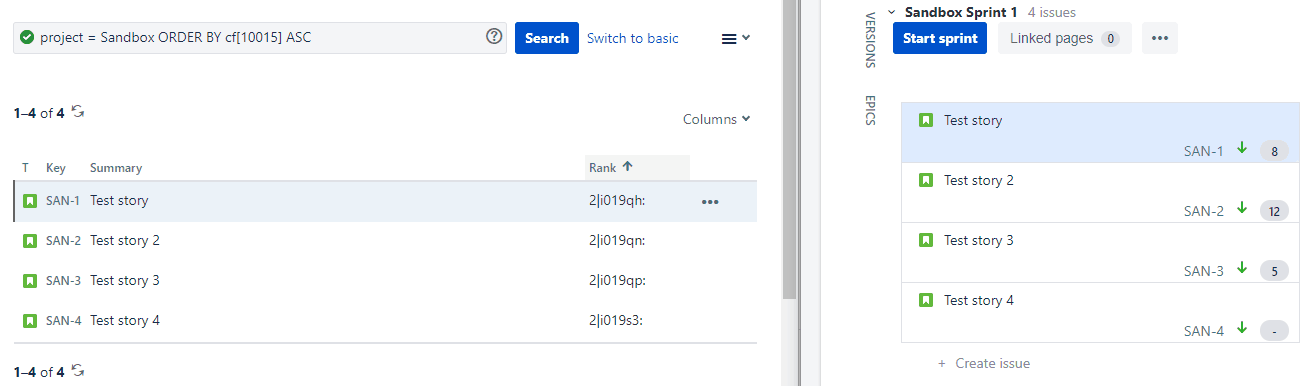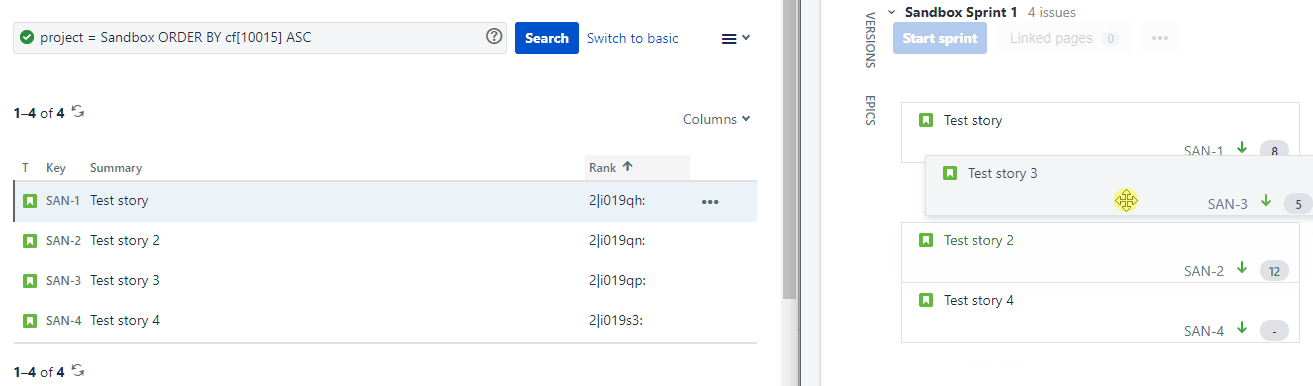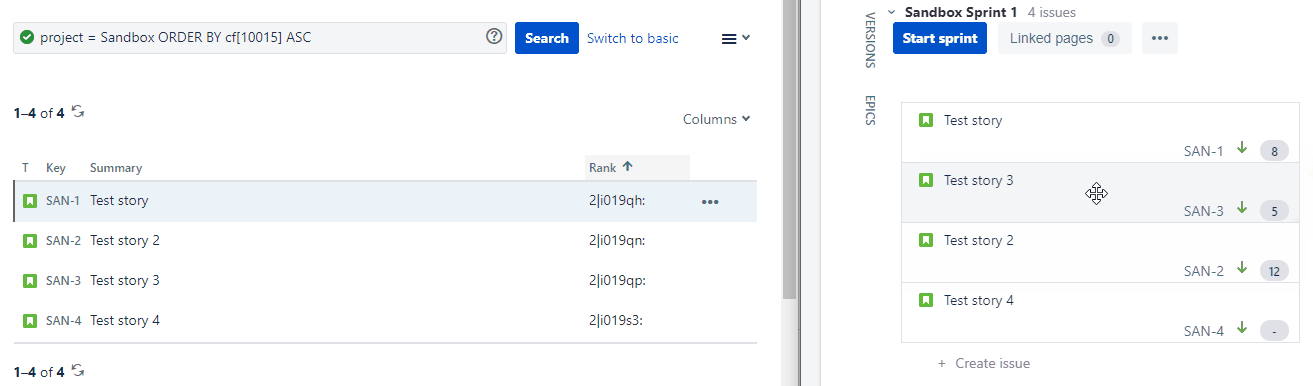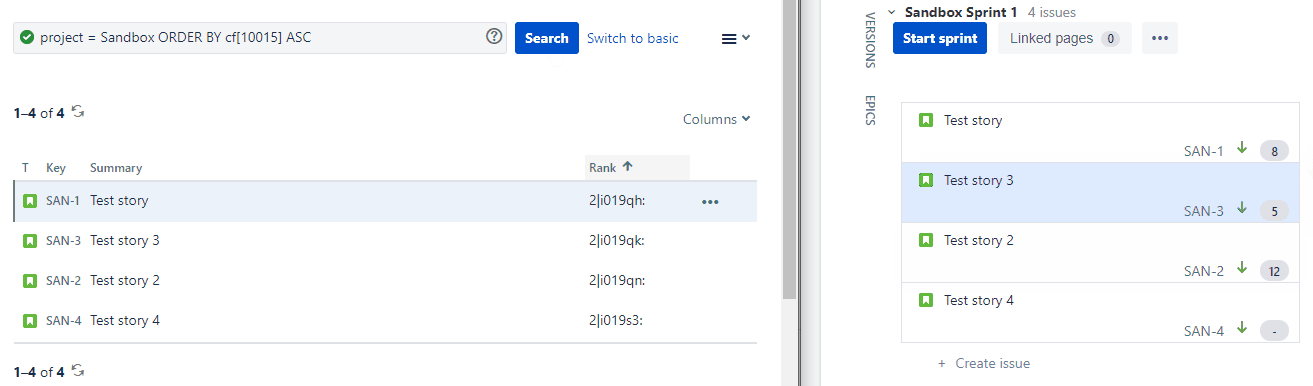
We have 4 stories:
| Key | Summary | Rank |
|---|---|---|
| SAN-1 | Test story | 2|i019qh |
| SAN-2 | Test story 2 | 2|i019qn |
| SAN-3 | Test story 3 | 2|i019qp |
| SAN-4 | Test story 4 | 2|i019s3 |
When we drag SAN-3 from below SAN-2 to above SAN-2, it’s Rank field value gets updated from 2|i019qp to 2|i019qk as can be seen below:
For the alphanumerical order, this means that SAN-3 still has a higher value than SAN-1 but this value is now lower than that of SAN-2.
Balancing buckets
LexoRank is actually the 3rd generation of the Jira issue ranking system and has been part of Jira since version 6.7. Before that, a ranking system was in place that used a reference to the issue that was ranked below the current issue. The first ranking system used numeric ranking values, e.g. 100, 200, 300. You can imagine that, when dragging issues, Jira would quickly run out of values to be able to keep ranking issues. To solve this, Jira had and still has a feature called rebalancing.
Back then, a rebalance would evenly distribute the rank values between the ranked issues, creating enough room between rank values to continue ranking issues. The downside, however, was that the whole system would be locked until the rebalance was finished, just like with a Full re-index on Jira Server.
With LexoRank, as the amount of issues grows and users perform more ranking operations, the length of these ranking values increases. A rebalance will evenly distribute the ranked issues and significantly reduce the rank length. When the rank value reaches a threshold, a rebalance is scheduled within the next 12 hours.
During a rebalance, ranking operations can continue as normal. This is because of buckets. A bucket is basically a container that holds all ranking values. Jira has 3 buckets (0, 1 and 2) of which only one is used unless a rebalance is taking place.
In the example above, bucket 2 is used. This can be seen in the prefix of the value in the Rank field, e.g. 2|i019qh. So the value before the pipe (vertical bar) character, indicates the bucket that is currently used.
During a rebalance the newly assigned issue ranks will be stored in the next bucket, in this case, bucket 0. Once the rebalance is completed, all issue ranks will be part of bucket 0 and thus have the prefix 0|. After another rebalance it will be 1 and so on.
The LexoRank management page
No matter which platform (Cloud, Server or DC) your Jira Software instance is on, they all have a LexoRank management page, which can be found in Jira’s system settings (System Settings → LexoRank management). The page helps you manage and troubleshoot the LexoRank system.
Below you can see a Jira Server screenshot from this page in which we numbered the various parts that make up this page, each of which will be explained.
The Jira Cloud’s version of this page looks similar but is somehow less graphical.
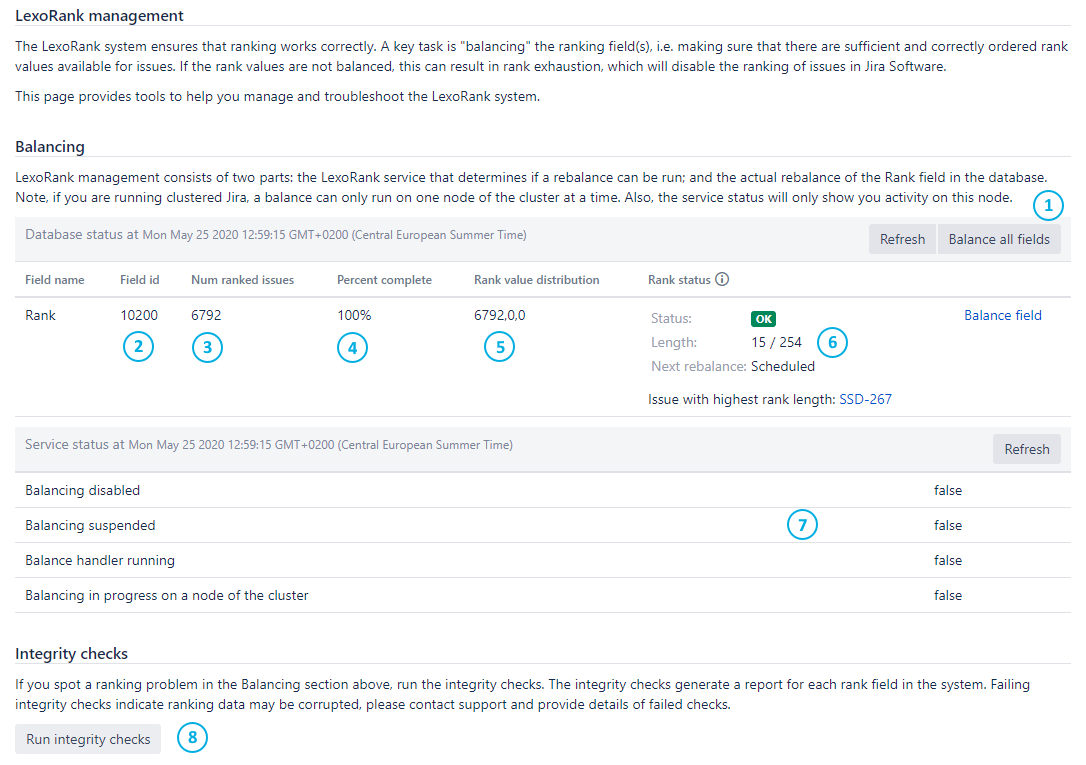
| Number | Item | Details |
|---|---|---|
| 1 | Balance fields button | Manually start a rebalance |
| 2 | Field id | Displays the id of the custom field that holds the ranking value for each issue |
| 3 | Number of ranked issues | The total number of issues that have a value in the Rank field |
| 4 | Percent complete | Indicates how far a rebalance operation is |
| 5 | Rank value distribution | Displays in which bucket (0,1,2) the ranked values are currently stored. When a rebalance is running, you will notice the number of ranked issues is distributed over 2 buckets and during normal operation, only one bucket will contain all ranked values. |
| 6 | Rank status | Status – OK – the rank length is in a healthy state – Warning – a rebalance has been scheduled – Critical – an immediate rebalance has started, you are approaching a state where rank operations will be disabled Length Indicates how many alphanumeric values currently make up the ranking values and how many values is the maximum length (when rank operations will be disabled). Next rebalance – Scheduled – once the next threshold is reached, a rebalance will be scheduled – Immediate – once the next threshold is reached, a rebalance will start immediately Issue with highest rank length This will tell you which issue has the longest rank. This can be useful to diagnose the cause of a rapid increase in rank length, i.e. a very enthusiastic product owner in a certain project. |
| 7 | Service status | Balancing disabled If this is true then Jira Software has disabled balancing internally: – A foreground re-index may be running. It is expected that this will disable balancing. – Jira Software may have just been installed / upgraded and requires a reminded. – Check the logs for any exceptions and see if there are existing KB articles for these errors. – See if there is anything failing in the Integrity checks. Balancing suspended This will be false unless balancing has been explicitly suspended by Support or an administrator. Balance handler running – This will be false unless a balance is currently in progress. To verify the progress of the balance, hit the refresh button. – On a Jira Data Center cluster this will be true on the node that is running the balance, and false on the other nodes. Balancing in progress on a node of the cluster – It indicates that the balance cluster lock has been taken. – This will be true when a balance is running. |
| 8 | Run integrity checks button | This runs a series of tests against the LexoRank data and returns a true / false result based on the test. |
LexoRank automatic rebalancing
At some point, the rank value length reaches a threshold, and a rebalance is scheduled within the next 12 hours.
Should the rank value length reach a second threshold within 12 hours, an immediate rebalance is started.
Should the rank value length reach a third threshold before the rebalance is finished, all rank operations are disabled until the rebalance completes.
Troubleshooting LexoRank
You might be confronted with issues regarding ranking or LexoRank at some point. If so, it’s good practice to review the integrity check results first, before manually starting a rebalance or diving into the logs.
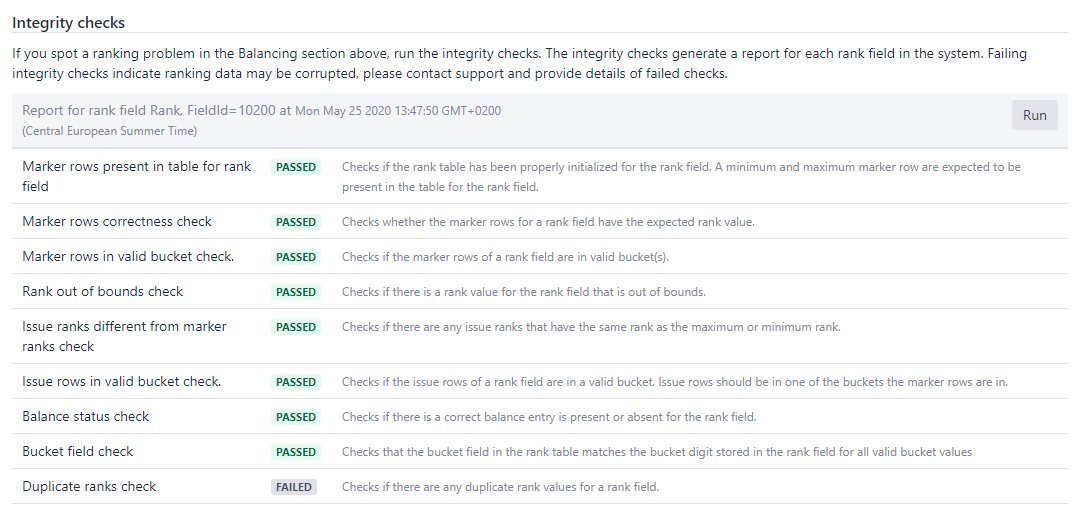
In the screenshot above, you can see the Duplicate ranks check has failed. Luckily, for a great number of these checks, Atlassian has troubleshooting articles. In this case, you could follow the How To Fix Duplicate Rank Values For a Rank Field article. But only if you are experiencing problems because of this.
For the other checks, the following fix details can be applied:
Marker rows indicate the minimum and maximum values of the current rank values. There are 3 types of marker rows:
– Type 0 is the smallest rank value (e.g. 000000)
– Type 2 is the largest rank values (e.g. ZZZZZZ)
– Type 1 are all rank values in betweenPer Jira instance, there should thus be only one Type 0 and Type 2 marker rows and a great number of Type 1 marker rows.
| Check | Fix details |
|---|---|
| Marker rows present in table for rank field. | If this fails, the minimum or maximum marker rows are missing. |
| Marker rows correctness check. | If this fails, the minimum or maximum marker rows exist, however they have the incorrect rank. This can be fixed by updating the rank on the row returned in the check to be the expected value. |
| Marker rows in valid bucket check. | When a balance is in progress, the marker rows are moved to another bucket to indicate where the new rank values should be. The only time they should be in different buckets is when a balance is in progress. Valid states for the marker rows are the below. – Minimum is the same as maximum. – Minimum is 0, and max is 1. – Minimum is 1, and max is 2. – Minimum is 0, and max is 2. This test fails if the marker rows are not in those buckets, and is likely caused by exceptions thrown during the rank creation or rebalance operation. Please check the logs for those and verify them against known problems. |
| Rank out of bounds check. | Please refer to the How to Fix Rank Out Bound Error KB article for the fix. |
| Issue ranks different from marker ranks check. | The below SQL will identify records that have ranking values the same as the min/marker rows. Deleting these records will correct this problem (and also result in a loss of ranking data for those issues only!).1 SELECT * FROM "AO_60DB71_LEXORANK" WHERE ("RANK" LIKE '%|zzzzzz:' OR "RANK" LIKE '%|000000:') AND "TYPE" not in (0,2);This may require changing depending upon the database type that is used. |
| Issue rows invalid bucket check. | If a rebalance can’t fix this, it would need detailed analysis from Atlassian Support. |
| Balance status check. | Attempt a rebalance, and check the logs to see if there are any exceptions. It’s likely the rebalance is failing due to an exception in the logs, or one of the other checks above may be failing. |
When an integrity check failed, it might be a good idea to contact Atlassian support first, before performing operations you might not be comfortable with. Cloud customers should, in all cases, immediately contact Atlassian support.
Ranking tips and tricks
- On a board or backlog, you can use keyboard shortcuts to move selected issues to the top or bottom, e.g. re-rank issues:
- Use sb to move them to the bottom.
- Use st to move them to the top.
- Alternatively, you can right-click on an issue or a selection of issues to move them to the top or bottom of the board or backlog.
- Ranking sub-tasks is a bit different:
- When you rank the parent issue, all of the sub-tasks are automatically re-ranked with the issue.
- Sub-task issues can only be ranked in relation to their ‘sibling’ issues, e.g. sub-tasks with the same parent.
- If you queried every issue in Jira and ordered them by Rank, then the rank field would begin at 1 and increase consecutively except for sub-tasks. They are ranked first by their parent then by their own rank. This means that sub-tasks are always ranked immediately next to their parent regardless of the absolute ranking index value.
- Ranking can be enabled or disabled on board level. The JQL query that powers the board needs to end with the exact following to enable ranking: ORDER BY Rank ASC. Remove the order or change the order to priority (for example) to disable ranking.
- If you are unable to Rank issues, even though the board is configured correctly, check if you have the correct project permissions. To be able to rank issues you need to have ‘Schedule Issue’ and ‘Edit Issue’ permissions in the project where the issue resides.
- When moving an issue to another project, their absolute ranking index value is retained, but only until you re-rank the issue of course.
- When dragging an issue to another column on a Scrum or Kanban board, you might unknowingly change the ranking.
- Rank changes are logged in the issue’s history.
- Unique for Advanced Roadmaps (formerly Portfolio) is that re-ranking a parent will re-rank both the parent itself and all its children (e.g. an epic with its stories). This does not happen when you re-rank an epic on a Jira board or backlog.
- When importing an issue export with their original rank value mapped to the Rank field, Jira will use the original rank values from the export. Though this will retain the relative ranking between the imported issues, it could also create duplicate rank values. Check out the How To Fix Duplicate Rank Values For a Rank Field KB article for a fix.
Hope you learned something and enjoyed the read!