This blog will provide information on making a backup of your Atlassian cloud instance and how you can create a backup strategy that is complementary to what Atlassian provides. We will share key details about why this is still an important topic even in this era of Cloud computing. We will explain the difference between redundancy, and backups and why these are two completely different topics. And why these are important aspects.
With many new Atlassian customers onboarding to Cloud this subject is becoming more and more relevant.
Cloud is the main focus for Atlassian, see our blog on Atlassian’s Cloud first strategy for more information about how Atlassian is accelerating our journey to the cloud.
Where server customers had extensive backup strategies this is not always covered in a cloud environment. Most customers who are starting in the cloud or migrating to the cloud assume that Atlassian takes full care of their data and backup strategy.
Well… Yes and no.
Let’s dive into the subject and start clarifying.
Atlassian is backing up my data right?
Yes, however, there is a but… Atlassian takes care of your instance and ensures that your instance is available pretty much 24/7 (99.9% for Premier and even higher for Enterprise grade plans).
It’s not so much a backup but Atlassian ensures that the data is there and with the least amount of outages. Basically, Atlassian provides data redundancy for all of its customers.
Also, for Atlassian, since customer site data is back-upped together with all other kinds of microservices it’s difficult to restore specific client data without affecting other services. Therefore it is not supported (source: https://support.atlassian.com/security-and-access-policies/docs/track-storage-and-move-data-across-products/ ).
This brings us to the next topic where the difference between backups and redundancy is explained. It’s important to understand these two topics and what they each have a specific use. A backup does not replace data redundancy and vice versa. This will be explained in the next chapter.
Real life example: in April 2022 Atlassian experienced an outage (ref: https://www.atlassian.com/engineering/post-incident-review-april-2022-outage ) where a limited amount of sites were affected. Affected customers without a backup were facing a complete outage for several weeks while customers with a backup strategy were able to limit the damage. With this in mind, it shows that a backup strategy, even in the cloud, is still relevant and valid. Even though as you can read in the incident review, Atlassian made huge changes to never ever let this happen again.
Backup vs Redundancy Explained
To understand the terminology it’s good to know the difference between these two topics. So let’s elaborate on them :
- Redundancy
- So what is redundancy and how is it defined? We would explain Redundancy, in the context of engineering, as: “the inclusion of extra components which are not strictly necessary to functioning, in case of failure in other components.”.
- The main purpose of Redundancy, in this case, is reliability and uptime. If there would be a hardware or network failure the data would not be able to be served to the customer.
- Redundancy can take place on storage (i.e. spare hard drives) but also on a network level (i.e. servers, load balancers). See the OSI model for all the levels with points of failure.
- Backups
- Where redundancy only protects against hardware or network failures a backup saves your data in case of human error like misconfiguration or deletion of data.
- For example, when accidentally deleting data. Redundancy does not help in this case as the deleted data is simply replicated to your redundant infrastructure.
- A backup, though, would still have the original data on a separate medium. The backup is ideally stored locally with copies stored externally. In case you download a copy of the cloud data to your laptop and your laptop fails then you’re still in the dark.
- The backup process would need to be fully automated and the integrity of the backup regularly checked. For example by restoring the content to another instance.
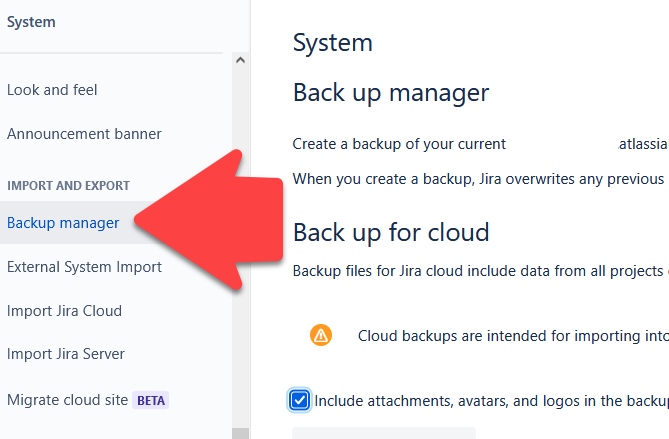
How to create (site) backups
Depending on the requirements, size, and complexity of the instance a partial/full, manual, or automatic backup can be performed.
To give you practical information on automating the backup of your Jira and or Confluence data we included some references to scripts below.
They support multiple platforms like Python, Powershell, Bash, etc. If this does not ring a bell, or you feel uncomfortable, then feel free to contact us.
Backing up Jira and Confluence Cloud
To make things easier, Atlassian provides multiple scripts to support you in this task.
After creating an API token and inserting your site name into the scripts you can initiate the creation of a backup. It will automatically download them to a designated address. Note that any data updated after the start of the backup is not included!
If you don’t feel comfortable doing this, contact us for support.
Note that the backups also contain data normally restricted by permissions. If any such data is available it is wise to encrypt the backups.
3rd Party Add-Ons
Don’t forget that some 3rd party add-ons can store (meta)data as well. Check with your 3rd Party Addon vendor if the data can be exported or if a backup can be created and restored. Note that when restoring to a different site 3rd Party data is lost.
Restoring data
But how to get that backed-up data back into your Atlassian cloud environment?
There are several ways:
TIP: It is recommended to create a new, temporary, Atlassian cloud or Sandbox environment to import the backup. This way the content of the backup can be verified. Using this method there are more options to export the data out of the backup site’. Before restoring the data in your test environment make a backup of your test environment. Atlassian will not let you restore data without a backup.
When using Confluence AND Jira there is no option for a Confluence Site import. Importing space by space is the only option in this case. With the exception of the Atlassian Backup CLI tool where a selection can be created.
Backup for Cloud
Use the Cloud migration tool to export selected data to your production site.
Limitations
Restoring data works and performs best on a high level (i.e. Confluence space / Jira project level). Restoring partial data, for example, a set of specific Jira issues or Confluence pages, from a backup is very limited. This would require a two-step recovery, where a project or space is restored and then the data is restored/imported to the existing site (with its limitations, for example not being able to restore the exact project keys).
There is also a trend where the “Trashcan” functionality is becoming more and more available to Atlassian products and objects. I.e. Jira Custom Fields, Projects and Confluence Spaces now have trashcan functionality where data is kept for 30 to 60 days before it is permanently deleted. So we might see that expanding to other objects as well.
Summary
Hope this blog provides more insight into why a backup strategy for your cloud products is still needed. Try to familiarize yourself with making backups and restoring to a dummy site.
From our experience, the Atlassian platform is very stable but human error accidents can still happen. Some real-life examples:
- Deleting field context can have the capability to lose massive amounts of potentially critical data with a few mouse clicks in the hands of an inexperienced administrator.
- Users/administrators performing erroneous bulk changes
- Deleting issues, components and or fix/versions. Since there is no trash-can functionality this is data is lost permanently. Of course this can be mitigated with proper permission schemes or changes in the workflow by allowing a “Cancelled” status.
Feel free to reach out!
If you still have questions after reading this blog or want us to advise or implement a backup strategy, feel free to reach out to us via our contact page to start a conversation.
We can provide you with hands-on knowledge and or tools to support your backup strategy.